
Technical Guides
How to Scrape Perplexity: API vs Web Interface
Learn how to scrape Perplexity with the official API, structured outputs, or web UI automation. Compare sources, citations, and trade-offs clearly.
Get the real Perplexity UI responses: numbered citations, related queries, query fan-out, plus auto-detected shopping cards, places, hotels, and videos. All the data the Perplexity Sonar API never returns. Markdown out, any country, any scale.
4.7 · 23 reviewscloro extracts the full Perplexity answer surface, and the same key gets you ChatGPT, Gemini, AI Overview, AI Mode, and Copilot.
Perplexity's consumer product is research-grade: numbered citations, related-question fan-out, sources panel. The Sonar API is a different surface, and the rich UI elements that drive brand visibility never come back.

Perplexity's anti-automation hardens with every UI release. A headless-browser pipeline buys you a few days before throttles cut your success rate in half. cloro absorbs the cat-and-mouse so your citation tracking keeps running when DIY scrapers get throttled.
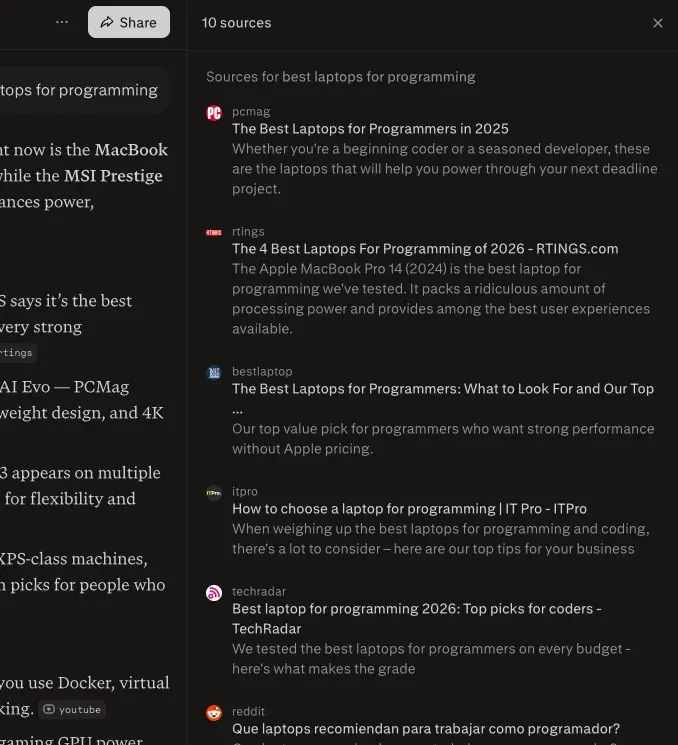
Perplexity re-ranks its numbered citations every time the same prompt runs, even within the same hour. A single Sonar call tells you nothing about coverage. You need repeated sampling across regions and time to see the real distribution. cloro returns the in-session ordering on every request so drift surfaces as data, not anecdotes.
The Sonar API returns model output with raw citation URLs but strips the information that defines the surface a real user sees. Surfer's analysis measured ~20% overlap between API responses and the rendered UI across LLMs.
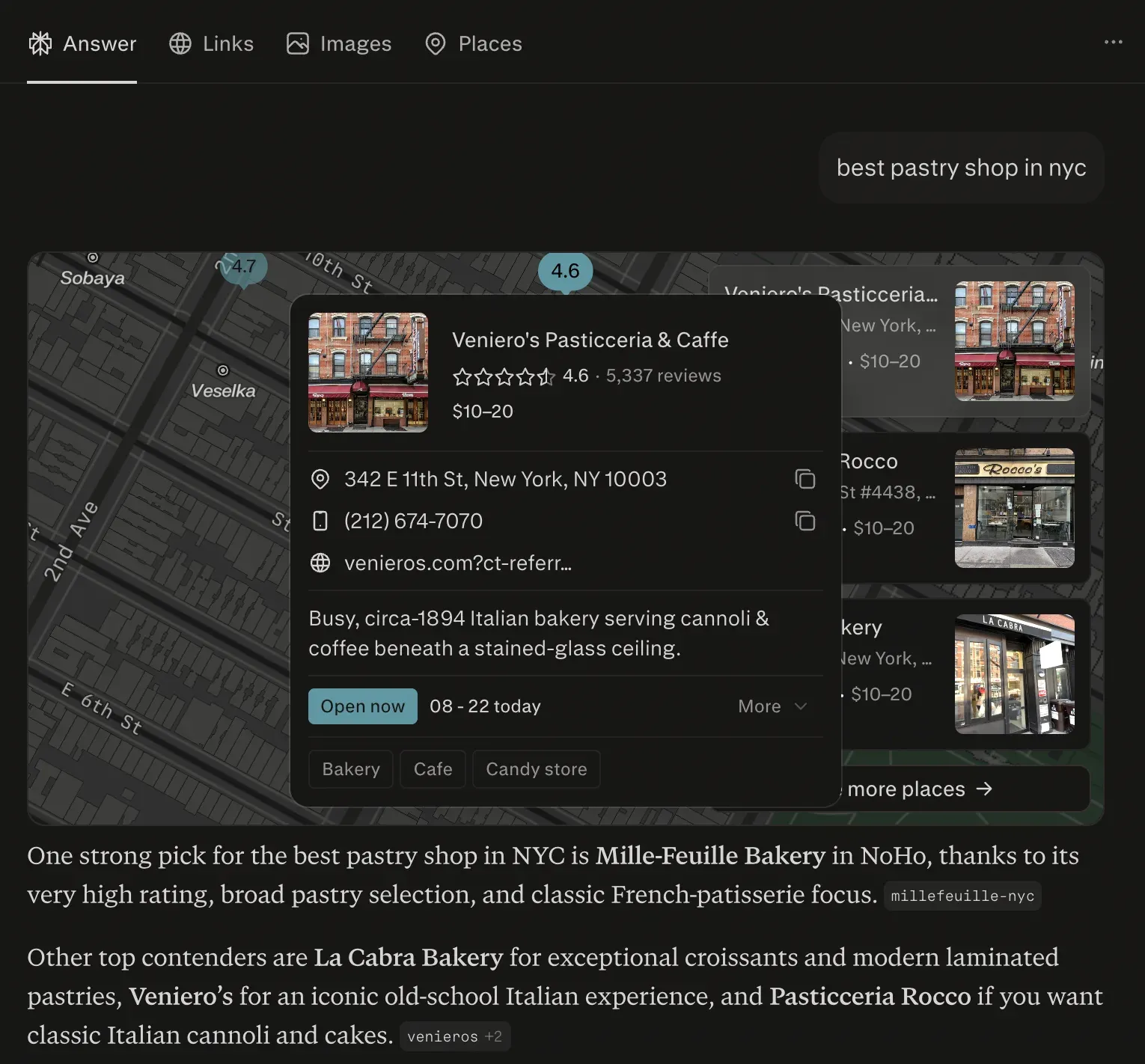
Perplexity auto-detects intent and renders specialized cards: shopping cards, places for local intent, hotels for travel intent, plus videos/images for media-rich queries, alongside query fan-out. None of this lives in the Sonar API. cloro returns it all as structured JSON.
Parse markdown, sources with snippets, shopping cards, query fan-out, and related questions from one endpoint.
import requests
response = requests.post(
"https://api.cloro.dev/v1/monitor/perplexity",
headers={
"Authorization": "Bearer sk_live_your_api_key_here",
"Content-Type": "application/json"
},
json={
"prompt": "What are the latest developments in renewable energy?",
"country": "US",
"include": {
"markdown": true
}
}
)
print(response.json()){
"success": true,
"result": {
"text": "Based on recent developments, Tesla's...",
"sources": [
{
"position": 1,
"url": "https://tesla.com/blog/fsd-beta-v12",
"label": "Tesla FSD Beta v12 Update",
"description": "Latest improvements in Tesla's autonomous..."
}
],
"html": "<div class=\"markdown\"><h2>Tesla Recent Developments</h2><p>Based on...</p></div>",
"markdown": "## Tesla Recent Developments\n\nBased on recent developments...",
"related_queries": [
"Tesla FSD Beta v12 review",
"Tesla Model Y price 2026"
],
"search_model_queries": [
{
"query": "Tesla FSD Beta v12 release notes",
"engine": "web",
"limit": 8
}
],
"shopping_cards": [
{
"products": [
{
"title": "Tesla Model Y",
"brand": "Tesla",
"price": "$43,990",
"rating": 4.5,
"reviewCount": 2847,
"imageUrl": "https://example.com/tesla-model-y.jpg",
"productUrl": "https://tesla.com/modely"
}
],
"tags": [
"electric",
"suv"
]
}
]
}
} Pick a plan that fits your volume. Price per credit drops as you scale.
Increased concurrency, overages on credits and credit discounts for annual contracts.
Know moreCredit cost per request varies by provider. The rates below apply to async/batch requests; sync requests add a +2 credit surcharge.
Google News uses the same pricing as Google Search.
Sonar returns a model response with citation URLs but strips the source metadata, related-question suggestions, and shopping cards that determine whether a brand actually shows up to a Perplexity user. The Sonar API is for building products on top of Perplexity's model. cloro is for understanding what real users see when they use perplexity.com.
Because Perplexity re-ranks its citation list per session. The same prompt run twice in the same hour can return different positions for the same sources. Caching would mask that drift, which is the signal you want to track. Every cloro request hits Perplexity live and returns the in-session ordering.
From our sampling: roughly 40% overlap on the same prompt between US and EU runs. The other 60% is region-specific (local-language sources, regional outlets, country-tagged X posts). If you only sample one region, you're seeing less than half your real Perplexity surface area. Pass `country` per request to capture the rest.
Yes. The response includes `related_queries` (the follow-up suggestions Perplexity surfaces under each answer, prime second-click real estate) and `search_model_queries` (the internal sub-queries Perplexity ran to compose the answer, each entry with `query`, `engine`, and `limit`). The latter are the long-tail terms your content needs to rank for to be cited at all.
Depending on prompt intent, the response can include `shopping_cards` (products with pricing, ratings, merchant offers), `places` (locations with categories, maps, ratings), `hotels` (with addresses, coordinates, images), and `videos`/`images` (media objects with thumbnails). cloro returns each as structured JSON without you needing to detect intent or write parsers.
Don't poll synchronously. Citation re-ranking happens fast enough that you want a webhook-driven feedback loop instead. Submit a batch via `POST /v1/monitor/perplexity/async`, receive results when they land, dump into your time-series store, alert on rank changes. Sync polling burns concurrency you don't need to spend.
Responses take 8–15 seconds each, and Perplexity's anti-automation tightens on long sessions. A DIY pipeline running daily citation tracking on a few hundred prompts needs sustained residential-proxy rotation plus a browser farm. Call it $4–6k/month before someone has to fix it. cloro covers the same workload on the Hobby plan ($100/month).
Learn how to scrape Perplexity with the official API, structured outputs, or web UI automation. Compare sources, citations, and trade-offs clearly.
We tested 12 LLM visibility tracking tools on real brand-monitoring workflows across ChatGPT, Perplexity, Gemini, and Google AI Overview. What works, what doesn't.

Should you build or buy AI search visibility tracking? Compare platform costs, API spend, engineering hours, maintenance, and break-even points.