Monitoring
The Best AI Visibility Tools in 2026 (Tested & Compared)
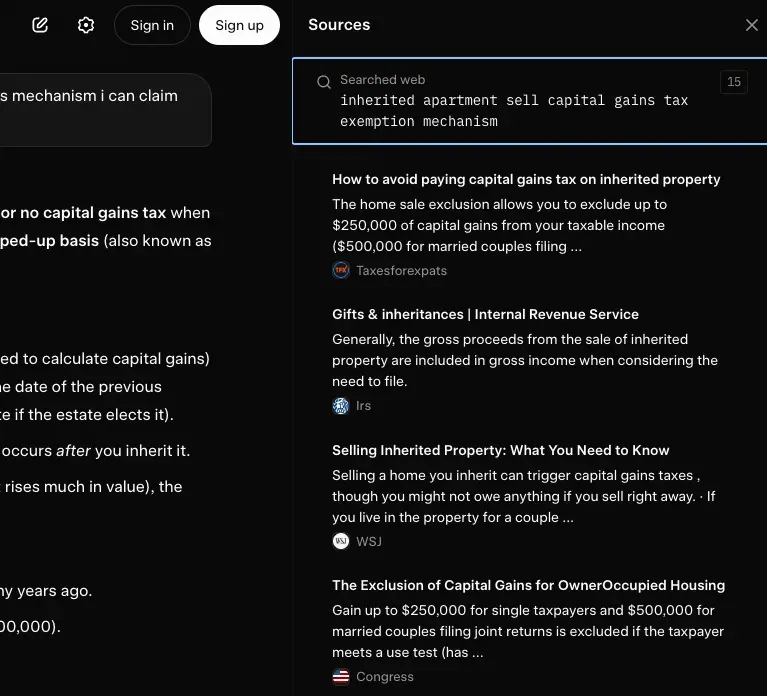
We tested 15 AI visibility tools (a.k.a. LLM visibility trackers) on real brand-monitoring workflows across ChatGPT, Perplexity, and Gemini. What works, what doesn't.
Get the real Grok responses with rich source metadata, including all the data the xAI API never returns. Markdown out, any country, any scale.
4.8 · 42 reviewsGrok extraction is temporarily unavailable
Grok has blocked anonymous access for the time being. Requests to this endpoint will fail.
cloro extracts Grok's X-grounded answers with full source metadata. The same key also gets you ChatGPT, Perplexity, Gemini, AI Overview, AI Mode, and Copilot.
Grok is the only AI search engine wired into a real-time content stream (X). That makes it the most volatile surface to monitor and the one richest in trending-brand signal. The xAI API ships with rate-limit caps that make sustained brand monitoring impractical.

X runs some of the most aggressive anti-automation on the public web, and Grok inherits that defense. DIY pipelines measure uptime in hours rather than days, and burn through six-figure proxy budgets to maintain sub-50% success rates. cloro absorbs the access fight so sustained Grok monitoring is actually possible.
Unlike ChatGPT or Gemini, whose grounding indexes refresh in days or weeks, Grok cites X posts published in the last 30 minutes. The same prompt run twice an hour apart returns substantially different citation sets. A daily snapshot misses nearly everything. Hourly sampling is what catches the trending content layer that drives Grok's brand-visibility signal.
The xAI API is invitation-gated, rate-capped, and returns model output without the rich source metadata. Surfer's analysis measured ~20% overlap between API responses and the rendered UI across LLMs.
Grok citations carry fields no other AI engine exposes. These are trust signals your dashboards should use to evaluate citation quality. None of it lives in any API endpoint. cloro returns all of it as structured JSON.
Parse markdown, rich source metadata (creator, preview, image, favicon), and citations from one endpoint.
from cloro import Cloro
client = Cloro(api_key="sk_live_your_api_key_here")
response = client.monitor.grok(
prompt="What are the latest developments in quantum computing 2026?",
country="US",
state="CA",
include={"markdown": True},
)
print(response["result"]["text"]){
"success": true,
"result": {
"text": "Recent developments in quantum computing include breakthrough error correction methods, increased qubit stability, and practical applications in cryptography...",
"model": "grok-4-auto",
"sources": [
{
"position": 1,
"url": "https://example.com/quantum-breakthrough",
"label": "MIT Technology Review",
"description": "Scientists achieve 99.9% qubit fidelity in room temperature conditions..."
}
],
"html": "...",
"markdown": "**Recent developments in quantum computing** include breakthrough error correction methods...",
"searchQueries": [
"quantum computing breakthroughs 2026",
"qubit fidelity room temperature"
]
}
}Break it down by element: Sources
Start free. Price per credit drops as your volume grows — see every tier below.
| Plan | Price / mo | Credits | Per 1k | Concurrency | Seats | Support |
|---|---|---|---|---|---|---|
| Free | $0 | 500 | — | 1 | 1 | Community |
| Lite | $30 | 37,500 | $0.80 | 10 | Unlimited | |
| Hobby | $100 | 250,000 | $0.40 | 20 | Unlimited | |
| StarterPopular | $250 | 650,000 | $0.39 | 50 | Unlimited | |
| Growth | $500 | 1,350,000 | $0.37 | 75 | Unlimited | Priority email |
| Business | $1,000 | 2,800,000 | $0.36 | 100 | Unlimited | Priority email |
| Enterprise 2K | $2,000 | 5,871,025 | $0.34 | 135 | Unlimited | Slack |
| Enterprise 3K | $3,000 | 9,306,606 | $0.32 | 175 | Unlimited | Slack |
| Enterprise 4K | $4,000 | 12,756,261 | $0.31 | 215 | Unlimited | Slack |
| Enterprise 5K | $5,000 | 16,391,783 | $0.31 | 255 | Unlimited | Slack |
| Enterprise | $5,000+ | Increased concurrency, overages on credits and credit discounts for annual contracts.Know more | ||||
Two reasons. First, xAI access is gated, so you may not get the rate limits brand monitoring requires. Second, the API returns model output without the rich source metadata (creator, preview, image, favicon) that Grok's UI surfaces. cloro extracts the full rendered surface and abstracts the access layer.
Grok cites X posts as recent as the last 30 minutes. For brand monitoring, hourly or every-2-hour sampling is the floor. Daily is too slow for trending content. cloro doesn't charge differently for higher cadence: same cost per request whether you query monthly or hourly.
Each citation includes URL, label, description, plus Grok-specific fields. No other AI search engine exposes this level of metadata. cloro returns all of it as structured JSON.
Every Grok request cloro runs hits the live grok.x.com surface, with no intermediate cache and no stale snapshot. Typical end-to-end latency is 30-60 seconds. If you query Grok at 10:15 about something that broke at 10:10, the citations you get are the citations a real Grok user would get at 10:15. That's the only useful behavior for trend monitoring.
Less than Gemini or Copilot, because X is a single global graph rather than a federated index. The *trending* content layer is heavily region-skewed though: what's hot on X in JP at 9 AM is invisible to a US-only sample. Pass `country` per request to capture the regional trending mix that drives a meaningful chunk of Grok's citation list.
For brand or topic monitoring, hourly is the floor and 15-minute is the ceiling. Anything slower misses trending content. Anything faster wastes budget on duplicates. Hourly × every tracked prompt × 24 hours adds up, so fire the batch via `POST /v1/monitor/grok/async` and ingest webhooks. Sync polling at this cadence is impractical.
X runs some of the most aggressive anti-automation on the public web. DIY pipelines measure their uptime in hours rather than days. We've watched in-house Grok scrapers burn through six-figure proxy budgets just to maintain sub-50% success rates. cloro absorbs that fight. The Hobby plan ($100/month) covers the workload at a steady success rate that DIY teams can't reach at any price.
We tested 15 AI visibility tools (a.k.a. LLM visibility trackers) on real brand-monitoring workflows across ChatGPT, Perplexity, and Gemini. What works, what doesn't.

Compare the best AI search engines for research and developers: ChatGPT, Perplexity, Gemini, Copilot, Brave, You.com, Exa, Tavily, and more.
AI search tracking means monitoring your brand across 7+ engines, not just ChatGPT. Get the playbook: what to measure, how often, and which tools work.