
Optimization
How to Get ChatGPT to Recommend Your Website
Learn how to get ChatGPT to recommend your website: content structure, authority signals, and technical fixes that lift your link inclusion rate.
Counterfeit listings, typosquats, and impersonation sites do their damage when they rank — on Google, and now inside AI answers. cloro is the brand protection data layer: continuous SERP monitoring on your brand-term set, plus the AI surfaces (ChatGPT, Perplexity, Gemini, Copilot, Grok, AI Overview, AI Mode) no other provider covers. Your enforcement queue, our data.
4.8 · 33 reviewsBrand protection is the work of finding and shutting down abuse of your brand — counterfeit sellers, lookalike domains, trademark ad hijacking, content theft, and impersonation — before it costs you customers or revenue. The operational insight: abuse only matters where customers can find it, which makes the discovery surfaces themselves the right place to detect it.
Historically that meant monitoring Google results and ads on your brand terms. Today it also means the AI layer: customers ask ChatGPT and Perplexity "is this site legit?" and the answer cites whatever ranks. cloro provides the data layer for both — continuous SERP snapshots and parsed AI answers with their citations, feeding your enforcement queue.
Related guide
What makes an AI engine cite a site — the mechanics behind the recommendations customers now trust.
Read the analysisRelated guide
The operator syntax investigators use to find copied content, lookalike domains, and brand abuse.
See the operatorsA fake shop only matters when a customer can find it. cloro covers the discovery surfaces end to end: Google organic and sponsored results, Google News, and all 7 AI answer engines — ChatGPT, Perplexity, Gemini, Copilot, Grok, AI Overview, AI Mode. One key, one credit pool, one response shape.
Domain-registration feeds tell you a lookalike domain exists. SERP and AI-answer monitoring tells you it is reaching users — ranking on your brand terms, bidding on your trademark, or being cited when a customer asks ChatGPT "is this legit?". That reach signal is what prioritizes an enforcement queue.
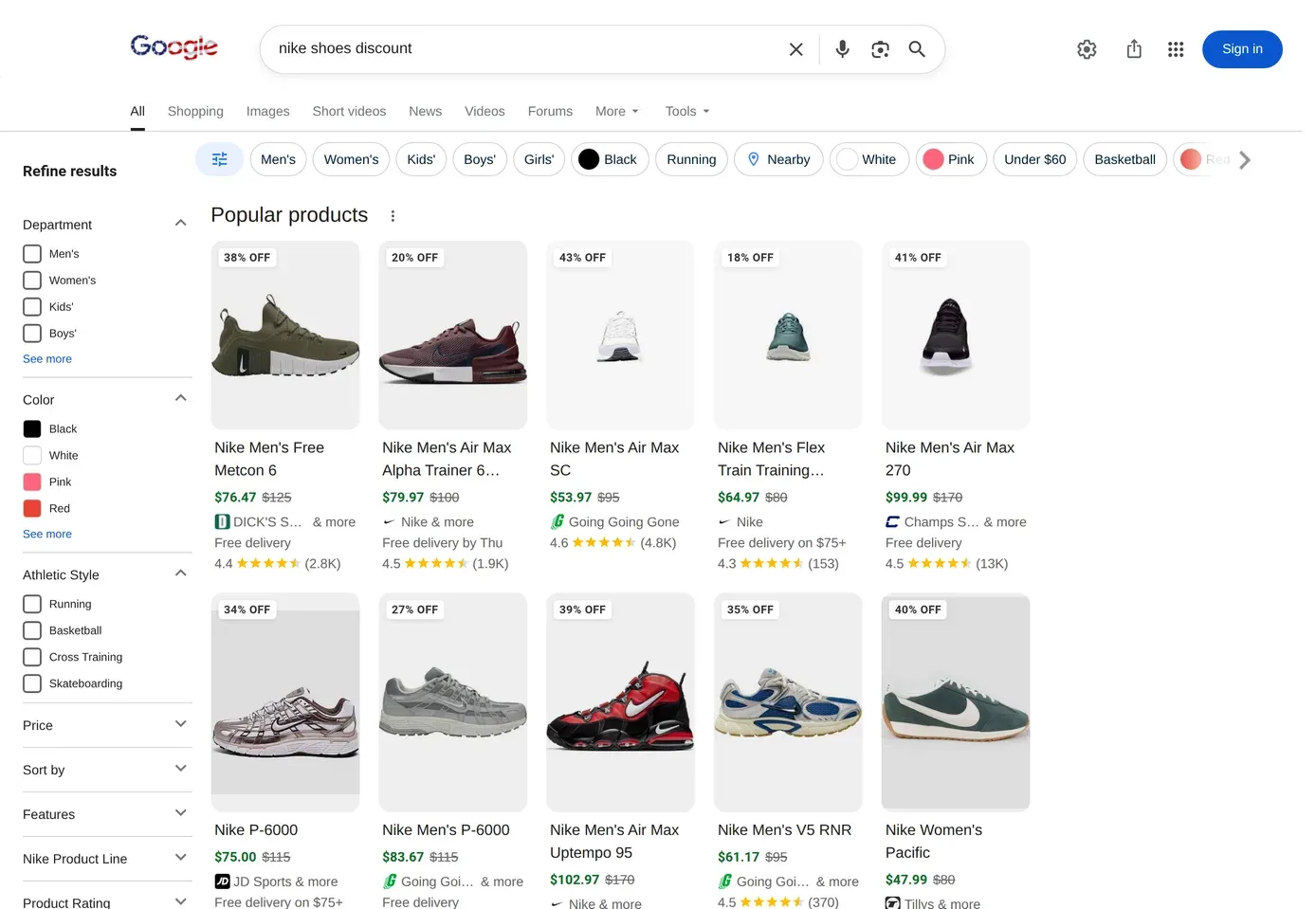
Fake shops don't wait to be found — they rank and advertise on "<brand> outlet", "<brand> discount", and "cheap <brand>" queries. Snapshot those SERPs daily, diff the domain set against your allowlist of legitimate retailers, and every new domain is an enforcement candidate with a timestamp, position, and URL attached. New-domain detection is a warehouse query, not a vendor feature gate.
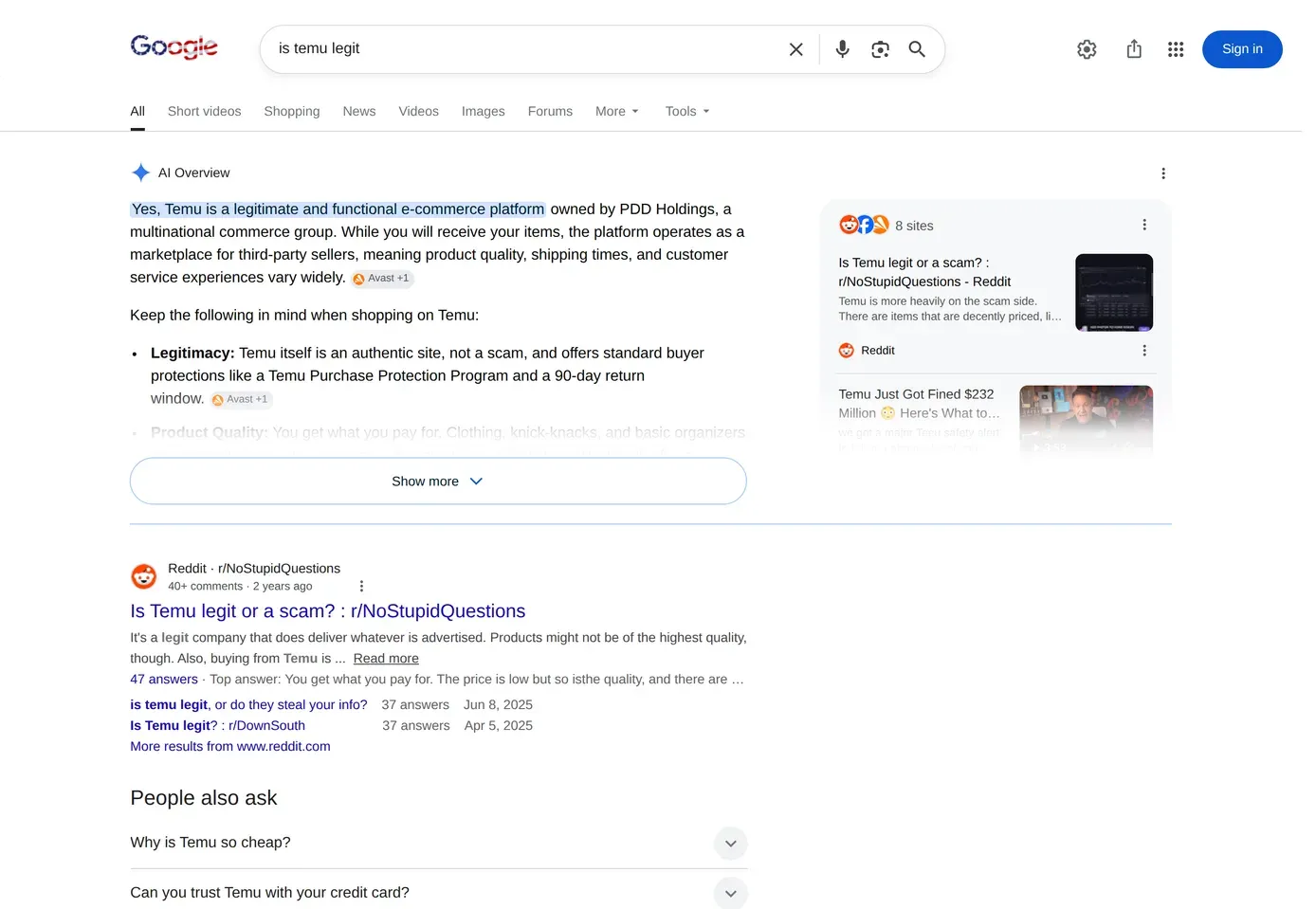
Customers ask ChatGPT and Perplexity "is <brand> legit?" and "where can I buy <brand> cheap?" — and the answer cites whatever ranks. Scam sites get cited, wrong brand info lands in AI Overviews, and no registrar feed or takedown vendor sees any of it. cloro returns the parsed answer text and cited sources from all 7 AI engines, so unauthorized domains in AI citations show up in the same pipeline as SERP hits.
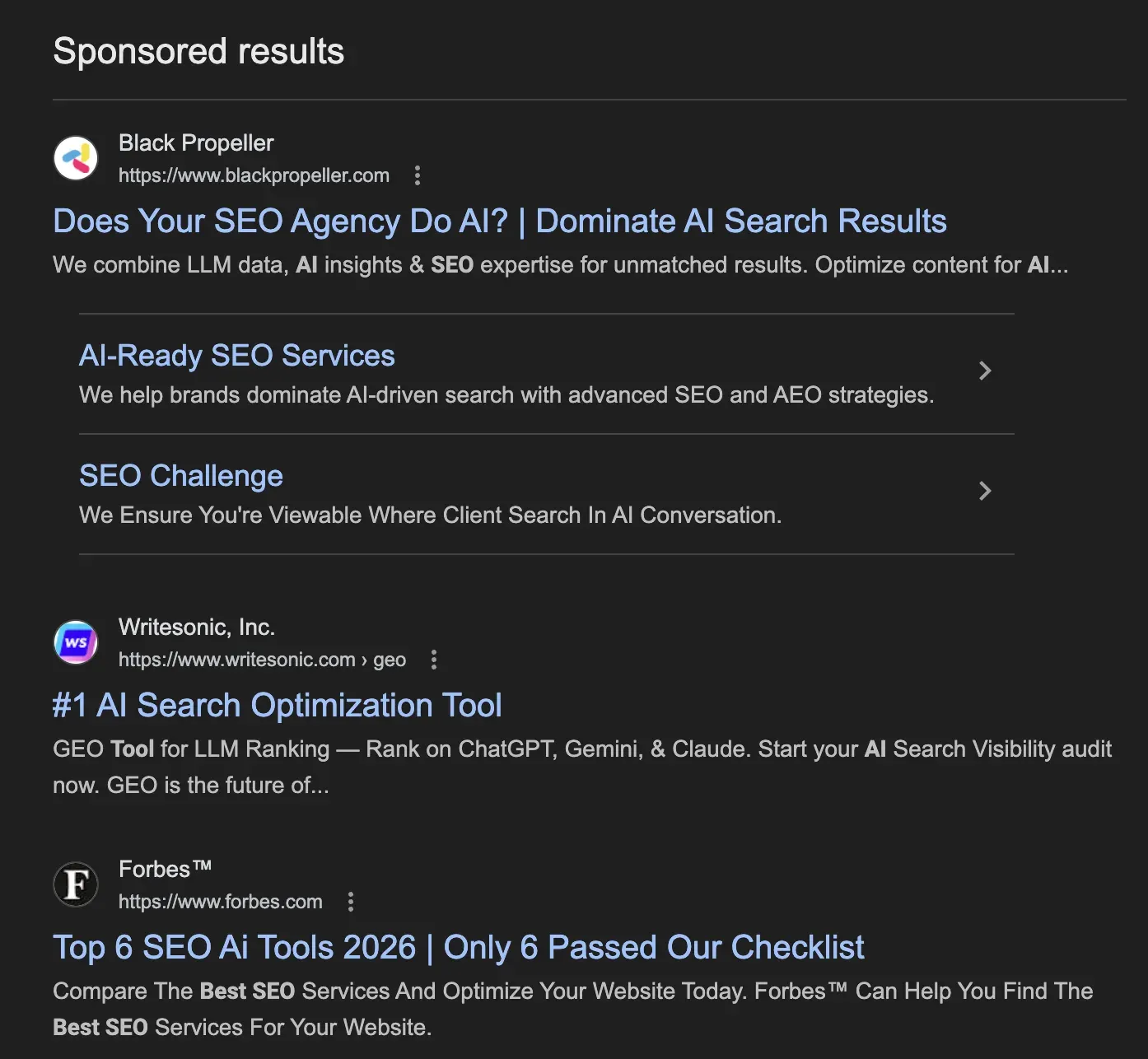
Competitors and scammers bidding on your trademark show up as parsed entries in the `ads[]` block of every SERP response: advertiser domain, position, creative text. Snapshot your brand queries hourly and you have a timestamped record of exactly who bid on your mark, when, and with what copy — the evidence trail a legal team needs before firing off a complaint.
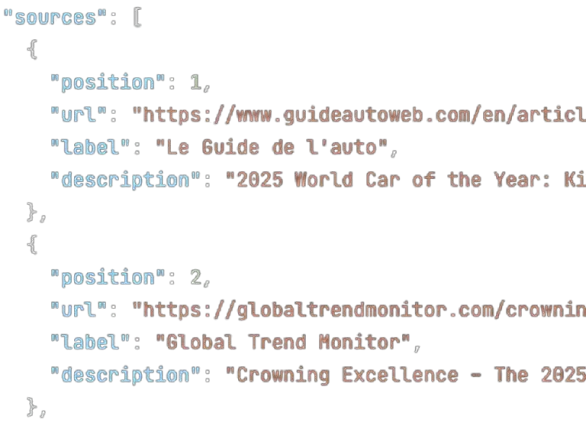
Thousands of lookalike domains get registered against any major brand; most never reach a single user. A typosquat becomes urgent when it ranks on your brand terms or gets cited by an AI engine. Monitoring SERP + AI-answer presence for your typosquat variant set turns an unrankable registration firehose into a short, prioritized enforcement queue — and every hit comes with the structured evidence (query, position, URL, timestamp) already attached.
The core recipe: brand/entity term set (brand name, product names, "<brand> discount", "<brand> outlet", typosquat variants) → continuous SERP + AI-answer snapshots → new-domain detection against your allowlist → enforcement queue. Your code, our data.
import requests
from urllib.parse import urlparse
# Brand-term set: brand, products, abuse modifiers, typosquat variants.
queries = [
"acme", "acme pro headphones",
"acme discount", "acme outlet", "cheap acme",
"acmee.com", "acme-store.shop",
]
# Domains allowed to appear on brand terms (your site + authorized retailers).
ALLOWLIST = {"acme.com", "amazon.com", "bestbuy.com"}
enforcement_queue = []
for query in queries:
response = requests.post(
"https://api.cloro.dev/v1/monitor/google",
headers={
"Authorization": "Bearer sk_live_your_api_key_here",
"Content-Type": "application/json",
},
json={"query": query, "country": "US", "device": "desktop"},
)
result = response.json()["result"]
hits = [
{"surface": "organic", "pos": r["position"], "url": r["link"]}
for r in result["organicResults"]
] + [
{"surface": "ads", "pos": a["position"], "url": a["url"]}
for a in result.get("ads", [])
]
for hit in hits:
domain = urlparse(hit["url"]).netloc.removeprefix("www.")
if domain not in ALLOWLIST:
enforcement_queue.append({"query": query, "domain": domain, **hit})
# Persist to warehouse; diff against yesterday's sweep for NEW domains.
for item in enforcement_queue:
print(item){
"success": true,
"result": {
"organicResults": [],
"ads": [],
"peopleAlsoAsk": [],
"relatedSearches": []
}
} Four brand-protection programs teams actually run on cloro data.
Daily sweeps of "<brand> outlet / discount / cheap" queries, diffed against a retailer allowlist — every new domain lands in the enforcement queue with position and timestamp attached.
Hourly `ads[]` snapshots on brand queries build a timestamped record of who bid on your mark, when, and with what copy — the evidence trail before the complaint goes out.
Per-tenant API keys and async webhook batching turn cloro into the SERP + AI-answer collection layer under your detection and enforcement product.
Daily "is <brand> legit" and "<brand> discount" prompts across ChatGPT, Perplexity, Gemini, Copilot, Grok, AI Mode, and AI Overview — flag every cited domain outside the allowlist.
Pick a plan that fits your volume. Price per credit drops as you scale.
Increased concurrency, overages on credits and credit discounts for annual contracts.
Know moreCredit cost per request varies by provider. The figures below are for async/batch requests; sync requests add a +2 credit surcharge.
ChatGPT full response includes query fan-out, ads, and shopping data. Google News uses the same pricing as Google Search.
Every `/v1/monitor/google` response includes a parsed `ads[]` block: advertiser domain, position, and creative text. Snapshot your brand and product queries hourly, filter `ads[]` against your allowlist of authorized advertisers, and any other domain bidding on your trademark surfaces immediately — with a timestamped record of the exact ad copy. Ads rotate continuously, so hourly is the right cadence for the ad surface; a daily sweep will miss dayparted campaigns.
Registration feeds tell you a lookalike domain exists; SERP presence tells you it's reaching users. Generate your typosquat variant set (character swaps, TLD swaps, hyphenations), then monitor two things: (1) SERPs for your brand terms — does the variant rank or advertise? — and (2) navigational queries for the variant itself, plus AI-engine answers citing it. A typosquat with zero SERP or AI-citation presence can sit at the bottom of the queue; one that ranks on "<brand> login" or gets cited by Perplexity is a today problem. cloro gives you the reach signal that prioritizes the registration firehose.
Yes — this is the classic recipe. Take exact distinctive phrases from your product pages or docs, search them as quoted queries via `/v1/monitor/google` (see Google search operators for the quoting patterns), and every ranking URL that isn't yours is a scraper candidate. The structured response gives you the evidence a DMCA notice needs: the query, the infringing URL, its position, and the retrieval timestamp — persisted in your warehouse, not screenshot folders. Re-run after sending the notice to verify the takedown actually landed.
Three prompt families: trust checks ("is <brand> legit", "is <brand>.com safe"), purchase-intent ("where to buy <brand> cheap", "<brand> discount code"), and navigational ("<brand> login", "<brand> customer service number" — a favorite of support-scam operators). Run them across ChatGPT, Perplexity, Gemini, Copilot, Grok, AI Mode, and AI Overview, and flag any cited domain outside your allowlist. Daily is the right floor — AI-engine citations churn faster than organic rankings. Only cloro covers all 7 AI surfaces; see AI visibility tracking for the measurement-side counterpart, and how ChatGPT picks what to cite for why scam sites get in.
No — and we'd rather tell you plainly than sell you a workaround. cloro has no image endpoints: no reverse image search, no Google Lens, no Images API. Visual counterfeit matching (logo detection, product-photo similarity) needs an image-recognition vendor; pair one with cloro if your program needs the visual layer. What cloro covers is the text half of brand protection — where the fake shops, ad hijackers, and impersonation sites actually reach customers: SERPs, sponsored results, news, and AI answers.
Pay-per-call: a Google SERP call is 3 credits (n=10), +2 per additional results page, +2 with AI Overview enrichment. A typical single-brand program — 100 brand/typosquat/modifier queries × 2 countries × daily = 6,000 SERP calls ≈ 18k credits/month, plus 25 impersonation prompts fanned across all AI engines daily (ChatGPT 5, Perplexity 3, Gemini 4, AI Mode 4, Copilot 5, Grok 4 credits — roughly 30 credits per prompt fan-out including an AI Overview-enriched SERP) ≈ 22.5k credits — lands around 40k credits, well inside the Hobby plan ($100/month, 250k credits). Platforms monitoring dozens of brand tenants scale into Growth ($500/month, 1.35M credits). Full breakdown on pricing.
The way IP-protection firms already run Google monitoring at scale: cloro as infrastructure, your platform as the product. Issue per-tenant API keys so each customer's usage meters separately, and drive collection through the async endpoints (`POST /v1/monitor/google/async` and per-engine `/v1/monitor/
Same infrastructure, different query sets and alert logic. SERP monitoring watches commercial keywords for competitive movement; brand protection watches brand/typosquat/abuse-modifier terms for unauthorized domains. Add news monitoring via `POST /v1/monitor/google/news` to catch press coverage of scams using your name, and adverse media screening if you also vet counterparties. One key and one credit pool cover all four programs.
Learn how to get ChatGPT to recommend your website: content structure, authority signals, and technical fixes that lift your link inclusion rate.

Use Google search operators to find exact phrases, PDFs, indexed pages, mentions, and competitor content. Includes examples and power-search workflows.

Yes — scraping public web data is legal in the US and EU when you respect CFAA, GDPR, robots.txt, and rate limits. 2026 guide with landmark cases, jurisdiction matrix, and EU AI Act rules.