
Technical Guides
Google Search Operators: Complete List and Examples
Use Google search operators to find exact phrases, PDFs, indexed pages, mentions, and competitor content. Includes examples and power-search workflows.
Exposed files, forgotten subdomains, phishing pages, and leaked references get indexed by search engines. cloro is the open-web reconnaissance layer for defenders: automate Google dorking and SERP recon on your own domains and brand terms, get structured JSON back, and feed it into your detection pipeline. It sees what Google and the AI engines surface — not the dark web, breach databases, or your network telemetry.
4.8 · 33 reviewsOpen-web threat intelligence is the practice of finding what public, search-indexed sources reveal about your organization's exposure — misconfigured hosts, forgotten documents, phishing pages impersonating you, and references leaked into indexed content. It is a subset of OSINT — in effect an OSINT API scoped to what search engines and AI answers can surface — and it is fundamentally a reconnaissance discipline: run the queries an attacker would, first, on your own scope.
It is deliberately one layer of a larger stack. It does not include the dark web, breach and credential databases, or network telemetry — those need dedicated tools. What it does cover, the search-indexed surface, is both the cheapest place for attackers to start and the one most defensive programs monitor least. cloro is the API for that layer, and it is careful to say where it stops.
Related guide
The operator syntax — site:, filetype:, inurl:, intitle: — that turns a search box into an exposure scanner.
See the operatorsRelated guide
How to discover a domain's full search-indexed footprint — the first step of an attack-surface audit.
Read the guidecloro covers exactly one thing well: what search engines and AI answers have indexed. Google organic results (with the full operator syntax), Google News, and all 7 AI answer engines — as structured JSON, on your cadence. It is not a dark-web feed, a breach-credential database, or a network sensor. Combine it with those tools; don't mistake it for them.
Attackers start reconnaissance where it's cheapest: a search box. Exposed configs, staging hosts, and phishing kits impersonating you are often one dork away — and already indexed. Defenders should run the same queries first, on a schedule, as structured data. That's the workload cloro is built for, and it stops exactly where the search index does.
A site: query against your own domain is the fastest external-attack-surface audit there is — it shows every subdomain, path, and document Google has indexed, including the staging host and the PDF nobody meant to publish. Run it as an API call on a schedule, diff against last week, and a newly indexed sensitive path becomes an alert instead of a breach post-mortem. This is EASM from the search-index side. See how to enumerate every indexed URL on a domain.
Search operators — filetype:, intitle:, inurl:, site: — turn Google into an exposure scanner. Attackers use them to find exposed assets; defenders should run the same queries first, on their own scope. cloro executes operator queries via /v1/monitor/google and returns parsed results, so a defensive dorking playbook becomes a scheduled job with structured output instead of manual searching. Authorized scope only — see the operator reference.
When someone asks an AI engine "is <domain> safe?" or "what is <company> known for," the answer is assembled from live web search and cites its sources. That is a reputation surface security and comms teams now have to watch — a phishing domain that gets cited, or a breach rumor an engine repeats. cloro returns the full AI answers with their citations across ChatGPT, Perplexity, Gemini, Copilot, Grok, AI Overview, and AI Mode.
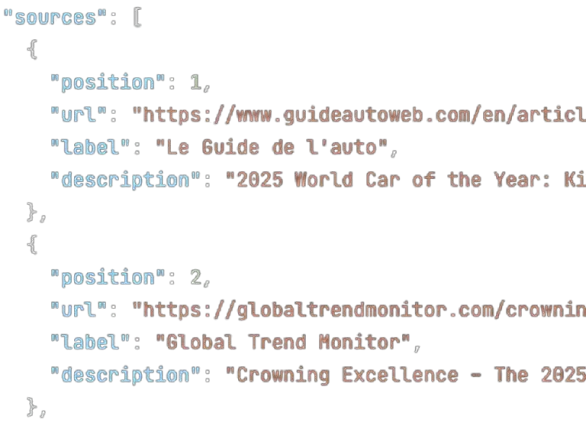
cloro returns open-web signals — the SERP and AI-answer presence of a domain, URL, or brand term — as structured JSON your pipeline can score. It does not pretend to be a scored reputation database, a dark-web monitor, a credential-leak service, or a threat-intel platform. Treat it as a high-signal input alongside those systems: a domain newly ranking for phishing-adjacent terms is a lead your enrichment stack confirms, not a verdict cloro issues.
The core recipe: your authorized scope (your domains, your brand terms) → a set of defensive dork queries → scheduled SERP snapshots → diff for newly indexed exposures → alert. Structured JSON out, your detection logic in the middle. Run it only against assets you own or are authorized to test.
import requests
from urllib.parse import urlparse
# AUTHORIZED SCOPE ONLY: your own domains / assets you're permitted to test.
DOMAIN = "example.com"
# Defensive dork playbook — surface exposures before an attacker does.
# Sanitized set; tune to your stack. Runs against YOUR domain only.
dorks = [
f"site:{DOMAIN} -www", # subdomains + stray hosts
f"site:{DOMAIN} filetype:pdf", # indexed documents
f"site:{DOMAIN} inurl:staging OR inurl:dev", # non-prod hosts indexed
f"site:{DOMAIN} intitle:\"index of\"", # open directory listings
]
findings = []
for dork in dorks:
response = requests.post(
"https://api.cloro.dev/v1/monitor/google",
headers={
"Authorization": "Bearer sk_live_your_api_key_here",
"Content-Type": "application/json",
},
json={"query": dork, "country": "US", "device": "desktop"},
)
for r in response.json()["result"]["organicResults"]:
findings.append({
"dork": dork,
"url": r["link"],
"host": urlparse(r["link"]).netloc,
"title": r.get("title"),
})
# Persist to your warehouse; diff against last run for NEWLY indexed exposures,
# then route new findings to your triage queue (Jira / TheHive / Slack).
for f in findings:
print(f){
"success": true,
"result": {
"organicResults": [],
"relatedSearches": []
}
} Four defensive open-web recon programs security teams run on cloro data — authorized scope only.
Scheduled site: sweeps of your own domains surface every indexed subdomain, path, and document — diffed for newly exposed assets before an attacker finds them.
Monitor brand-plus-login and typosquat queries for pages impersonating you — the search-visible slice of phishing, routed straight to takedown.
Turn a manual dork playbook into a scheduled job: operator queries against your scope, parsed results, deltas into your triage queue.
Per-tenant keys and async webhook batching make cloro the search-indexed collection source under your attack-surface or threat-intel platform.
Pick a plan that fits your volume. Price per credit drops as you scale.
Increased concurrency, overages on credits and credit discounts for annual contracts.
Know moreCredit cost per request varies by provider. The figures below are for async/batch requests; sync requests add a +2 credit surcharge.
ChatGPT full response includes query fan-out, ads, and shopping data. Google News uses the same pricing as Google Search.
cloro covers the search-indexed open web: what Google Search, Google News, and the AI answer engines surface for a query. That makes it a strong fit for Google dorking at scale, exposed-asset discovery, phishing-page surfacing, and open-web reputation signals. It explicitly does not cover the dark web, breach or credential-leak databases, network or endpoint telemetry, or scored threat-intel feeds. If a workload needs any of those, cloro is a complementary input — not the source. We would rather draw that line clearly than sell you a capability we don't have.
Querying a public search engine for content it has already indexed is a normal, legal activity — but what you do with the results is governed by authorization and law. Run reconnaissance only against assets you own or are explicitly authorized to test (your domains, an engagement in scope), respect the CFAA and your local equivalents, never access exposed data you find beyond confirming the exposure, and follow responsible-disclosure practice for anything you surface about a third party. cloro is data infrastructure; the authorization and compliance obligations sit with you. See the legal landscape for public-web data collection.
Encode your dork set as queries and run them through /v1/monitor/google on a schedule against your authorized scope. Operators like site:, filetype:, inurl:, and intitle: all work in the query string, and you get parsed results back instead of HTML to scrape (see the operator reference). Persist each run, diff against the last for newly indexed exposures, and route deltas to your triage queue. The point of automating it is coverage and cadence — a human dorking once a quarter misses what an attacker finds the week you ship a misconfiguration.
No — and the distinction matters. cloro returns open-web signals, not scores: the SERP and AI-answer presence of a domain or URL, as structured data. That is a genuine input to a reputation, IOC, or malicious-URL-detection pipeline — a domain suddenly ranking for phishing-adjacent brand terms, or a lookalike URL cited by an AI engine in a scam context, is a real signal — but cloro does not assign a reputation score or maintain a curated indicator list. Feed the signals into your own scoring, or into a dedicated reputation/IOC provider that does. Calling it a "feed input" is honest; calling it a "reputation database" would not be.
As the open-web collection layer. Attack-surface-management and threat-intel platforms correlate many sources — passive DNS, certificate transparency, breach data, network scans; cloro adds the one most of them under-cover: what search engines and AI answers have indexed about your assets and brand. Pipe cloro findings into your SIEM, SOAR, or ASM platform as another enrichment source. It is deliberately a component, not a replacement — which is why it embeds cleanly rather than competing with your platform of record.
Same open-web infrastructure, different query sets and intent. Brand protection watches brand and typosquat terms for counterfeit and impersonation — heavy overlap with phishing-page detection here. Adverse media screening shares the security/risk persona and the entity-monitoring pattern. And the AI-answer reconnaissance angle is the defensive mirror of AI visibility tracking. One API key and one credit pool cover all of them.
Pay-per-call: a Google SERP call is 3 credits (n=10), +2 per additional results page. A defensive program of 200 dork queries across your domains, run daily, is 200 × 30 × 3 = 18k credits/month — comfortably inside the Hobby plan ($100/month, 250k credits). Add a daily AI-answer reputation check on a set of monitored domains (ChatGPT 5 + Perplexity 3 credits per domain) and you're still well under it. Vendors running recon across many client scopes scale into Growth ($500/month, 1.35M credits) with per-tenant keys and async webhook delivery. Full breakdown on the pricing page.
Yes — that's the intended shape. Issue per-tenant API keys so each customer's recon usage meters separately, and drive collection through the async endpoints (`POST /v1/monitor/google/async` and per-engine `/v1/monitor/
Use Google search operators to find exact phrases, PDFs, indexed pages, mentions, and competitor content. Includes examples and power-search workflows.

From sitemaps to Python crawlers. Learn every method to discover every single page on a website, including hidden endpoints and orphan pages.

Yes — scraping public web data is legal in the US and EU when you respect CFAA, GDPR, robots.txt, and rate limits. 2026 guide with landmark cases, jurisdiction matrix, and EU AI Act rules.